
Поиск — важная часть приложения, и некоторые его пропускают, считая простой задачей. «Да просто добавлю несколько LIKE и готово!». И, хотя LIKE на самом деле может быть удобным, иногда нам приходится использовать более надежную поисковую систему.
Одним из самых популярных способов является использование Elasticsearch. Это очень мощный инструмент, он поставляется с множеством полезных функций и дополнительных инструментов. Здесь мы рассмотрим основы и дадим несколько ссылок на дополнительные ресурсы, если вы вдруг захотите узнать больше.
Что такое Elasticsearch?
С официального сайта :
Elasticsearch — это распределенный поисковый и аналитический движок, лежащий в основе Elastic Stack. Logstash и Beats облегчают сбор, агрегацию и обогащение ваших данных и их хранение в Elasticsearch. Kibana позволяет вам в интерактивном режиме исследовать, визуализировать и обмениваться информацией о ваших данных, а также управлять и контролировать стек. Elasticsearch — это место, где происходит волшебство индексации, поиска и анализа.
Другими словами: мы можем использовать Elasticsearch для логирования (см. Elastic Stack) и для поиска. В этой статье мы рассматриваем только использование поиска.
Основы Elasticsearch
Чтобы лучше понять этот инструмент, лучше начать с нуля, без сравнения с SQL. Прежде всего, Elasticsearch документоориентирован и поддерживает REST, поэтому его можно использовать на любом языке. Давайте углубимся в его основные понятия.
Индекс и типы
Документоориентированность подразумевает, что мы ищем, сортируем, фильтруем и т.д. Документы. Документ представлен в формате JSON и содержит информацию, которая может быть проиндексирована. Обычно мы храним (индексируем) документы с похожими структурами отображения (полями) вместе, это мы и называем индексом. Например, может быть один индекс для пользователей, другой для статей, третий для товаров.
Внутри индекса могут быть один или несколько типов. У нас обычно один тип, но иногда полезно иметь несколько. Допустим, есть сущность Contact, которая является родителем сущностей Lead и Vendor. Хотя мы могли бы хранить обе сущности в одном и том же типе «contacts» внутри индекса «contacts», но было бы лучше хранить их в отдельных типах, поэтому делаем типы «leads» and «vendors».
Стоит сказать, что Elasticsearch не имеет схемы, но не является бессхемным, это означает, что мы можем индексировать все, что захотим, и это определит типы данных, но мы не можем иметь одно и то же поле, содержащее разные типы данных. Чтобы получить качественные результаты поиска и избежать непредвиденного поведения, мы должны определить типы данных для каждого поля и придерживаться их.
Более подробно вы можете прочесть в документации.
Локальная среда
Предполагаю, что у вас еще не запущен Elasticsearch на вашем локальном компьютере. Мы собираемся использовать Docker, но не волнуйтесь, вы можете запустить его без Docker, следуя официальной документации, я просто хотел еще немного поиграться с Docker.
Установите Docker и docker-compose на свой компьютер и запустите:
docker run -d -e "discovery.type=single-node" \
-e "bootstrap.memory_lock=true" \
-p 9200:9200 \
elasticsearch:6.8.1
Если у вас нет образа Elasticsearch Docker на компьютере, то он возьмет его из реестра, поэтому в первый раз это может занять некоторое время.
- флаг
-dозначает, что мы хотим запустить его отдельно, другими словами: не блокируя терминал; - флаг
-eустанавливает некоторые переменные окружения в контейнере. Нам нужны здесь две, одна для того, чтобы указать, что это кластер с одним хостом, а другая включает SWAP, если Elasticsearch не хватает памяти; - параметр
-p 9200:9200говорит Docker, что мы хотим, чтобы порт 9200 привязан к нашему localhost:9200.
Если у вас есть какие-либо проблемы с настройками vm_max_map_count, то смотрите документацию.
Если всё хорошо, то вы можете сделать curl-запрос для проверки работы сервера Elasticsearch:
curl localhost:9200
{
"name" : "BtziAML",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "qW73OEpQSq-k7uCsc3gCnQ",
"version" : {
"number" : "6.8.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "1fad4e1",
"build_date" : "2019-06-18T13:16:52.517138Z",
"build_snapshot" : false,
"lucene_version" : "7.7.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
Подобный ответ означает, что можно продолжать дальше. Если вы не получаете ответа, возможно, ваш сервер Elasticsearch всё еще загружается. Проверьте, работает ли сам контейнер с помощью docker ps (так и должно быть).
Демо-приложение
Для начала нам нужные ДАННЫЕ для использования Elasticsearch, поэтому в этом примере у нас есть команда seeder, которая заполняет базу данных и, одновременно, индексирует все данные в Elasticsearch (через Наблюдателя — Observer). Я покажу это позже, сначала давайте посмотрим, как мы можем интегрировать это с нашими моделями Eloquent.
Вы можете создать приложение Laravel с помощью composer или с помощью установщика Laravel, например так:
laravel new es-laravel-example
Теперь у вас есть готовое приложение Laravel. Но, так как мы собираемся использовать Elasticsearch в этом приложении, давайте установим его
composer require elasticsearch/elasticsearch
Генерируем каркас аутентификации
php artisan make:auth
Если вы запустите php artisan serve и зайдёте в браузере на localhost:8000, то вы увидите страницу приветствия:
Для демки мы собираемся использовать концепцию статей. Итак, нам нужно создать модель Article и ее миграцию. Мы можем сделать это, выполнив: php artisan make:model -mf Article, где флаг -m указывает создать миграцию для этой модели, а -f создает фабрику моделей.
Нужно настроить миграцию, в папке database/migrations/ должен быть новый файл с именем create_articles_table и префиксом DateTime.
Откройте его и установите поля, которые мы будем использовать, например, так:
Schema::create('articles', function (Blueprint $table) {
$table->bigIncrements('id');
$table->string('title');
$table->text('body');
$table->json('tags');
$table->timestamps();
});
Поскольку мы используем поле tags как массив, нам необходимо настроить под это нашу модель.
Откройте модель Article.php и пропишите:
namespace App;
use Illuminate\Database\Eloquent\Model;
class Article extends Model
{
protected $casts = [
'tags' => 'json',
];
}
Нужно создать сидер для нашей модели, для генерирования данных. Запустите php artisan make:seeder ArticlesTableSeeder и откройте его. Внутри метода run() нужно добавить эти две строки:
use Illuminate\Database\Seeder;
class ArticlesTableSeeder extends Seeder
{
public function run()
{
DB::table('articles')->truncate();
factory(App\Article::class)->times(50)->create();
}
}
После создания ArticlesTableSeeder зарегистрируйте его в database/seeds/DatabaseSeeder.php:
public function run()
{
$this->call(ArticlesTableSeeder::class);
}
Сидер использует функциональность ларавельной Model Factory для того, чтобы создать 50 фейковых статей. Но мы это еще не настроили. Откройте файл database/factories/ArticleFactory.php и добавьте новую запись:
/* @var $factory \Illuminate\Database\Eloquent\Factory */
use App\Article;
use Faker\Generator as Faker;
$factory->define(Article::class, function (Faker $faker) {
$tags = collect(['php', 'ruby', 'java', 'javascript', 'bash'])
->random(2)
->values()
->all();
return [
'title' => $faker->sentence(),
'body' => $faker->text(),
'tags' => $tags,
];
});
Добавим шаблон и маршрут, чтобы мы можно было выводить список статей:
@extends('layouts.app')
@section('content')
<div class="container">
<div class="card">
<div class="card-header">
Articles <small>({{ $articles->count() }})</small>
</div>
<div class="card-body">
@forelse ($articles as $article)
<article class="mb-3">
<h2>{{ $article->title }}</h2>
<p class="m-0">{{ $article->body }}</body>
<div>
@foreach ($article->tags as $tag)
<span class="badge badge-light">{{ $tag}}</span>
@endforeach
</div>
</article>
@empty
<p>No articles found</p>
@endforelse
</div>
</div>
</div>
@stop
Мы используем директиву blade, которая выполняет цикл с $articles и выводит список статей.
Пришло время запустить наш сидер. Но мы еще не настроили нашу базу данных, давайте используем SQLite только потому, что она проще. Запустите:
touch database/database.sqlite
В файле .env чтобы изменить учетные данные БД на:
DB_CONNECTION=sqlite
Удалите все остальные строки с DB_*. Остановим через php artisan serve (если он все еще работает) и запустим снова для перезагрузки конфигов. Пришло время начать миграцию и заполнить нашу базу данных. Запустите php artisan migrate --seed. Откройте приложение в своем браузере (на localhost: 8000). Вы должны увидеть что-то вроде этого:
Давайте реализуем конечную точку поиска. Сначала через простой SQL. Интерфейс репозитория для извлечения данных будет примерно таким:
namespace App\Articles;
use Illuminate\Database\Eloquent\Collection;
interface ArticlesRepository
{
public function search(string $query = ''): Collection;
}
Реализация Eloquent будет такая:
namespace App\Articles;
use App\Article;
use Illuminate\Database\Eloquent\Collection;
class EloquentRepository implements ArticlesRepository
{
public function search(string $query = ''): Collection
{
return Article::query()
->where('body', 'like', "%{$query}%")
->orWhere('title', 'like', "%{$query}%")
->get();
}
}
Забиндим интерфейс в AppServiceProvider следующим образом:
namespace App\Providers;
use App\Articles;
use Illuminate\Support\ServiceProvider;
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
$this->app->bind(
Articles\ArticlesRepository::class,
Articles\EloquentRepository::class
);
}
}
Круто. Теперь добавим поле поиска в шаблон:
@extends('layouts.app')
@section('content')
<div class="container">
<div class="card">
<div class="card-header">
Articles <small>({{ $articles->count() }})</small>
</div>
<div class="card-body">
<form action="{{ url('search') }}" method="get">
<div class="form-group">
<input
type="text"
name="q"
class="form-control"
placeholder="Search..."
value="{{ request('q') }}"
/>
</div>
</form>
@forelse ($articles as $article)
<article class="mb-3">
<h2>{{ $article->title }}</h2>
<p class="m-0">{{ $article->body }}</body>
<div>
@foreach ($article->tags as $tag)
<span class="badge badge-light">{{ $tag}}</span>
@endforeach
</div>
</article>
@empty
<p>No articles found</p>
@endforelse
</div>
</div>
</div>
@stop
Должно получиться так:
Работает! Отлично! И теперь, наконец, можно реализовать поиск через Elasticsearch.
Интеграция Elasticsearch
Поскольку Elasticsearch говорит о REST, то будем подключаться к моделям Eloquent, которые нужно проиндексировать и отправим HTTP-запросы в API Elasticsearch. Концепции, описанные здесь, я взял из Laracon Talk. Используется Laravel, но концепции могут быть применены к любому языку/фреймворку.
В этом примере мы будем использовать Наблюдателей (Model Observers). У нас есть обычная модель Eloquent, в нашем случае — Article. Мы можем написать трейт и наблюдателя, которые будут обрабатывать индексацию для всех наших моделей (тех, которые используют этот трейт), поэтому у нас будет что-то вроде:
namespace App\Search;
use App\Article;
use Elasticsearch\Client;
class ElasticsearchObserver
{
/** @var \Elasticsearch\Client */
private $elasticsearch;
public function __construct(Client $elasticsearch)
{
$this->elasticsearch = $elasticsearch;
}
public function saved($model)
{
$this->elasticsearch->index([
'index' => $model->getSearchIndex(),
'type' => $model->getSearchType(),
'id' => $model->getKey(),
'body' => $model->toSearchArray(),
]);
}
public function deleted($model)
{
$this->elasticsearch->delete([
'index' => $model->getSearchIndex(),
'type' => $model->getSearchType(),
'id' => $model->getKey(),
]);
}
}
Нужно привязать этого наблюдателя ко всем нашим моделям, которые мы хотим индексировать в Elasticsearch. Сделаем это, введя новый трейт для поиска. Он также предоставит методы, которые использует наблюдатель.
trait Searchable
{
public static function bootSearchable()
{
// Это облегчает переключение флага поиска.
// Будет полезно позже при развертывании
// новой поисковой системы в продакшене
if (config('services.search.enabled')) {
static::observe(ElasticsearchObserver::class);
}
}
public function getSearchIndex()
{
return $this->getTable();
}
public function getSearchType()
{
if (property_exists($this, 'useSearchType')) {
return $this->useSearchType;
}
return $this->getTable();
}
public function toSearchArray()
{
// Наличие пользовательского метода
// преобразования модели в поисковый массив
// позволит нам настраивать данные
// которые будут доступны для поиска
// по каждой модели.
return $this->toArray();
}
}
Зарегистрируем Наблюдателя в нашей модели:
namespace App;
use App\Search\Searchable;
use Illuminate\Database\Eloquent\Model;
class Article extends Model
{
use Searchable;
protected $casts = [
'tags' => 'json',
];
}
Теперь, когда мы создаем, обновляем или удаляем сущность, используя нашу модель Eloquent Article, это запускает Elasticsearch Observer для обновления своих данных в Elasticsearch. Обратите внимание, что это происходит синхронно во время HTTP-запроса, лучше использовать очереди и обработчик Elasticsearch, который асинхронно индексирует данные, чтобы не замедлять пользовательский запрос.
Репозиторий Elasticsearch
Теперь мы можем cкормить Elasticsearch наши данные. Оставим SQL-реализацию поиска как резервную, на случай сбоя серверов Elasticsearch. Создадим другую реализацию интерфейса репозитория:
namespace App\Articles;
use App\Article;
use Elasticsearch\Client;
use Illuminate\Support\Arr;
use Illuminate\Database\Eloquent\Collection;
class ElasticsearchRepository implements ArticlesRepository
{
/** @var \Elasticsearch\Client */
private $elasticsearch;
public function __construct(Client $elasticsearch)
{
$this->elasticsearch = $elasticsearch;
}
public function search(string $query = ''): Collection
{
$items = $this->searchOnElasticsearch($query);
return $this->buildCollection($items);
}
private function searchOnElasticsearch(string $query = ''): array
{
$model = new Article;
$items = $this->elasticsearch->search([
'index' => $model->getSearchIndex(),
'type' => $model->getSearchType(),
'body' => [
'query' => [
'multi_match' => [
'fields' => ['title^5', 'body', 'tags'],
'query' => $query,
],
],
],
]);
return $items;
}
private function buildCollection(array $items): Collection
{
$ids = Arr::pluck($items['hits']['hits'], '_id');
return Article::findMany($ids)
->sortBy(function ($article) use ($ids) {
return array_search($article->getKey(), $ids);
});
}
}
Мы выбрали поиск Elasticsearch, а затем выполнили поиск findMany SQL с полученными элементами. В предыдущих версиях этой статьи я рассмотрел еще один вариант, где мы гидратировали (hydrated) экземпляры модели из проиндексированных данных. Но я считаю, что смешанный подход Elasticsearch + SQL проще и менее подвержен ошибкам, так как мы можем выбрать индексирование только доступных для поиска данных вместо всех атрибутов модели.
Хитрость в переключении репозитория заключается в замене привязки в ServiceProvider следующим образом:
namespace App\Providers;
use App\Articles;
use Illuminate\Support\ServiceProvider;
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
$this->app->bind(Articles\ArticlesRepository::class, function () {
// Это полезно, если мы хотим выключить наш кластер
// или при развертывании поиска на продакшене
if (! config('services.search.enabled')) {
return new Articles\EloquentRepository();
}
return new Articles\ElasticsearchRepository(
$app->make(Client::class)
);
});
}
}
Всякий раз, когда мы запрашиваем интерфейсный объект ArticlesRepository из контейнера IoC, он фактически выдает экземпляр ElasticsearchRepository, если тот включен, в противном случае — Eloquent версию.
Нужно настроить клиент Elasticsearch, забиндить его в AppServiceProvider или создать новый. В нашем случае, используем существующий AppServiceProvider:
namespace App\Providers;
use App\Articles;
use Elasticsearch\Client;
use Elasticsearch\ClientBuilder;
use Illuminate\Support\ServiceProvider;
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
$this->app->bind(Articles\ArticlesRepository::class, function () {
// Это полезно, если мы хотим выключить наш кластер
// или при развертывании поиска на продакшене
if (! config('services.search.enabled')) {
return new Articles\EloquentRepository();
}
return new Articles\ElasticsearchRepository(
$app->make(Client::class)
);
});
$this->bindSearchClient();
}
private function bindSearchClient()
{
$this->app->bind(Client::class, function ($app) {
return ClientBuilder::create()
->setHosts($app['config']->get('services.search.hosts'))
->build();
});
}
}
Теперь, когда код почти готов, нам нужно закончить конфигурацию. Возможно, вы заметили использование вспомогательного метода config в некоторых местах. Он загружает данные файлов конфигурации. Вот, что у меня в config/services.php:
return [
// ...
'search' => [
'enabled' => env('ELASTICSEARCH_ENABLED', false),
'hosts' => explode(',', env('ELASTICSEARCH_HOSTS')),
],
];
Здесь мы говорим Laravel проверить переменные окружения, чтобы взять текущие настройки. Мы устанавливаем их локально в файле .env:
ELASTICSEARCH_ENABLED=true ELASTICSEARCH_HOSTS="localhost:9200"
Для случая с несколькими хостами мы делаем список, разделенный запятой, и в конфиге его разбиваем на отдельные хосты. Но в данный момент пока это не используется. Если у вас запущено через php-сервер, не забудьте перезапустить его, чтобы подгрузить новые настройки. Теперь нужно заполнить Elasticsearch нашими данными. Для этого нам понадобится специальная artisan команда. Создайте её через php artisan make:command ReindexCommand (см. код ниже). Эта команда также понадобиться нам позже, если нужно будет менять схемы индексов Elasticsearch, то мы сбросили бы текущие индексы и переиндекисровали каждый фрагмент данных (или использовали алиасы для нулевого времени простоя).
Создаем интерфейсную команду:
php artisan make:command ReindexCommand --command="search:reindex"
Откройте её и отредактируйте:
namespace App\Console\Commands;
use App\Article;
use Elasticsearch\Client;
use Illuminate\Console\Command;
class ReindexCommand extends Command
{
/**
* The name and signature of the console command.
*
* @var string
*/
protected $signature = 'search:reindex';
/**
* The console command description.
*
* @var string
*/
protected $description = 'Indexes all articles to Elasticsearch';
/** @var \Elasticsearch\Client */
private $elasticsearch;
/**
* Create a new command instance.
*
* @return void
*/
public function __construct(Client $elasticsearch)
{
parent::__construct();
$this->elasticsearch = $elasticsearch;
}
/**
* Execute the console command.
*
* @return mixed
*/
public function handle()
{
$this->info('Indexing all articles. This might take a while...');
foreach (Article::cursor() as $article)
{
$this->elasticsearch->index([
'index' => $article->getSearchIndex(),
'type' => $article->getSearchType(),
'id' => $article->getKey(),
'body' => $article->toSearchArray(),
]);
$this->output->write('.');
}
$this->info('\nDone!');
}
}
Теперь мы можем запустить эту команду, чтобы скормить наши данные серверу Elasticsearch:
php artisan search:reindex Indexing all articles. This might take a while... .................................................. Done!
Перезапуститесь: php artisan serve (чтобы презагрузить конфиги) и попробуйте что-нибудь поискать. Вы должны увидеть что-то вроде этого:
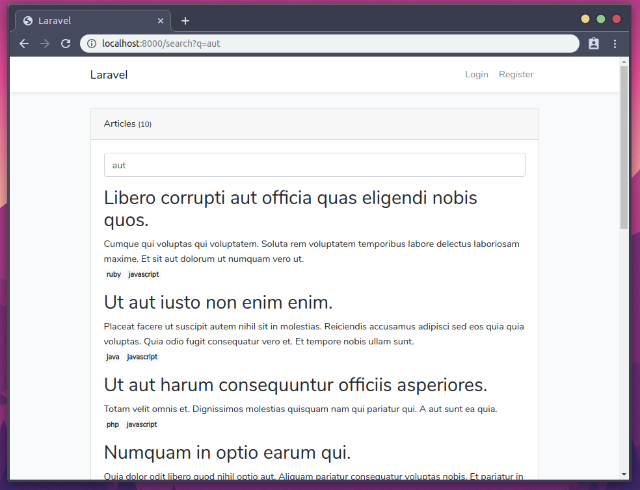
Мы могли бы достичь аналогичного результата и через простой SQL. Да, мы могли бы. Но в Elasticsearch есть и другие вкусняшки. Например, допустим, что вас больше интересует поиск по заголовку, чем по любому другому полю, плюс важен поиск по тегам, например:
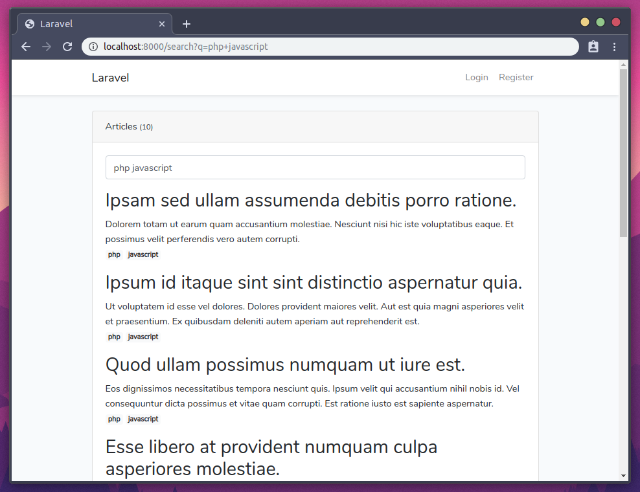
Проверьте, каждый из результатов имеет тег, либо PHP, либо Javascript, либо оба. Давайте определим правило релевантности для поля заголовка:
'query' => [
'multi_match' => [
'fields' => ['title^5', 'body', 'tags'],
'query' => $query,
],
],
Здесь мы определяем, что совпадения в поле заголовка в 5 раз более актуальны, чем в других полях. Смотрим:
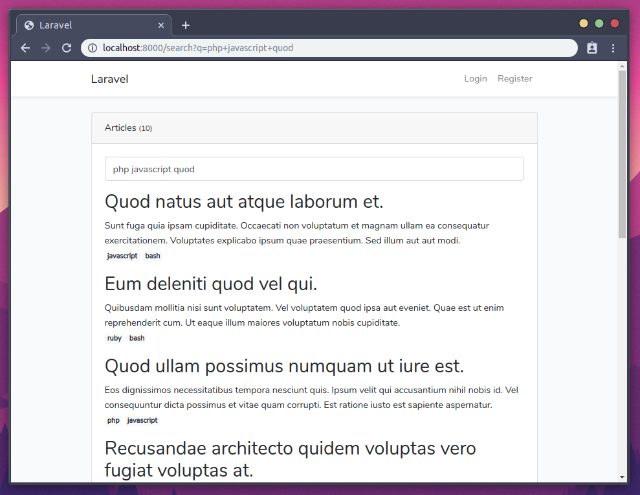
Первое совпадение не имеет искомых тегов, но заголовок совпадает с последним запросом, поэтому он выдается выше. Круто, нам всего лишь нужно было немного поменять конфиг.
Релевантность — весьма деликатная тема. Может потребоваться несколько встреч, обсуждений и прототипов, прежде чем вы и ваша команда сможете решить, как именно её использовать.
Завершение
Мы рассмотрели основы и способы интеграции вашего приложения Laravel с Elasticsearch. А вы знали, что у Laravel есть собственный официальный пакет полнотекстового поиска? Он называется Laravel Scout и поддерживает Algolia из коробки. Вы можете писать собственные драйверы. Вроде бы только для полнотекстового поиска. Например, если вам нужно выполнить какие-то необычные поиски с агрегацией, то вы можете написать свою собственную интеграцию.
Репозиторий, написанный на основе этой статьи: https://github.com/tonysm/laravel-elasticsearch-2019
Автор: Tony Messias
Перевод: Алексей Широков
Наш  Телеграм-канал — следите за новостями о Laravel.
Телеграм-канал — следите за новостями о Laravel.