
Я уже много лет использую Задачи и Очереди в Laravel. Поначалу мне было очень тяжело, у меня в голове не укладывалась их концепция, структурирование приложения, зависящее от них, все это казалось странным, если не сказать даже слишком сложным.
Но однажды у меня в голове щелкнуло и мне всё стал ясно. Надеюсь с вами произойдет тоже самое и потом вы будете удивляться как все эти годы жили без них.
Замечу, что основная проблема с обучением по этой теме (в контексте Laravel) заключается не в новизне материала, а в том что большинство учебных материалов в интернете, либо слишком теоретические, либо работают с такими простыми примерами, что и не встретишь в реальном мире.
Я пишу этот урок для себя прошлого. Он именно такой, по которому я бы хотел учиться, когда впервые столкнулся с этими понятиями. Мне нравится объяснять сложные идеи на примерах. Вместе с вами мы соберем простое аналитическое приложение, причем начнем с простейшей версии, как если бы мы были его единственными пользователями. Мы постараемся понять недостатки этого подхода и то, как Задачи и Очереди помогут нам исправить их и решить некоторые проблемы, с которыми мы столкнемся.
Описание приложения
Наше приложение (назовем его basic-analytics-v01) будет очень простым. Оно позволит нам отслеживать трафик нашего сайта.
Давайте создадим его, помня о том, что в дальнейшем мы можем захотеть открыть его и для других пользователей, поэтому нам нужно хранить данные пользователей отдельно. Также нам нужна возможность быстро и легко интегрировать приложение в существующие сайты.
Сайт будет отправлять POST-запрос на конкретную конечную точку нашего аналитического инструмента каждый раз, когда пользователь заходит на одну из его страниц. Затем мы вычисляем время, потраченное на каждую страницу, вычитая временные метки двух последовательных POST-запросов.
basic-analytics-v01
Мы сделаем это приложение (по крайней мере, его первую версию) действительно простым.
Давайте сосредоточимся на хранении этих заходов в базе данных. Все, что нам нужно, это конечная точка и контроллер (да, поместим всё в контроллер).
Во-первых, давайте создадим две основные модели, которые нам понадобятся, и их соответствующие миграции.
- Tracker: у каждого сайта будет свой уникальный трекер. Сейчас нам просто нужно убедиться, что ID трекера является валидным (то есть существует в базе данных) и уникальным.
- Hit: каждый POST-запрос будет сохранен как «Hit»
Код нашего контроллера:
class TrackingController extends Controller
{
public function track($tracker_public_id, Request $request)
{
$tracker = Tracker::where('public_id', $tracker_public_id)->first();
if ($tracker) {
$url = $request->get('url');
$hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $url]);
$previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first();
if ($previousHit) {
$previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at);
$previousHit->save();
return $previousHit->seconds;
}
return 0;
}
return -1;
}
}
Имейте в виду, что мы упрощаем многие вещи, нас интересует только тот пример использования, который поможет понять суть этой статьи.
Как вы можете видеть, в этом коде нет ничего плохого, особенно если учесть, что он для небольшого персонального сайта.
Но давайте представим варианты, когда этот код уже не будет достаточно хорош или просто сломается.
Время отклика
Допустим, что скрипт, который отправляет эти запросы, должен по той или иной причине дождаться подтверждения, что запрос получен.
Когда я это проверяю, отправляя запрос локально с помощью Postman, то вот что получаю:
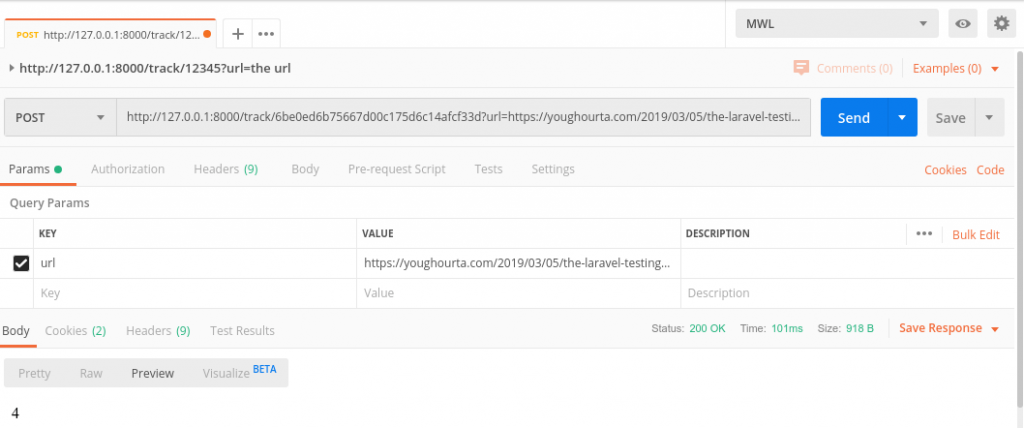
100 мс — это довольно долго, хотя мы в контроллере и не выполняем никакой существенной обработки. А представьте, что нам нужно выполнить дополнительные действия, плюс несколько запросов к базе данных или даже пообщаться со сторонним API. То есть мы заблокируем скрипт, отправляющий нам запрос (и возможно даже страницу, на которой выполняется этот скрипт), до тех пор пока мы не закончим обработку.
Количество одновременных запросов
Неважно, запускаете ли вы приложение локально или на продакшене, всегда существует лимит на количества запросов, которые вы можете обработать.
Если вы используете локальный сервер и запускаете свое приложение через php artisan serve, то вы заметите, что сервер может обрабатывать только один запрос за раз.
Если мы выполняем наш код синхронно, как сейчас, это означает, что мы чаще будем утыкаться в этот лимит, так как сохраняем загруженность вебсервера. Вскоре мы заметим, что множество запросов просто отваливается по таймауту. Чтобы решить это нам нужно как можно скорее освобождать соединение.
Потеря данных
Еще одна проблема, о которой не сразу и подумаешь, это сбой (например, нет доступа к базе данных, или ошибка в коде, выбрасывающая исключение) при котором мы не можем сохранить запрос и повторить попытку.
Теперь посмотрим, как использование Задач и Очередей поможет нам решить все эти проблемы.
Отправка Задач в Очередь
Сначала поговорим о том, что такое Очереди и Задачи.
В двух словах, Задача — это кусок кода (например, метод), который мы хотим выполнить. И мы помещаем его в Очередь, чтобы отложить его выполнение и делегировать «чему-то другому».
Покажу на примере из реального мира: когда вы приходите в фастфуд, то оператор, который принимает ваш заказ, будет не тем, кто его приготовит, но он убедится, что заказ принят правильно и делегирует остальную часть работы кому-то еще.
Причиной подобной цепочки в том, что оператору не нужно держать вас в очереди в ожидании, пока не будет готов ваш заказ, ему нужно выполнить минимально необходимую работу и перейти к следующему заказу, чтобы параллельно обслужить как можно больше людей. То же самое мы хотим реализовать в нашем коде.
Итак, нам просто нужно убедиться, что POST-запрос получен, а затем делегировать оставшуюся часть работы другой части приложения.
Один из способов сделать это — поместить код, который мы хотим делегировать, в замыкание и отправить его в очередь следующим образом:
dispatch(function () use ($parameters) {
// ваш код здесь
});
Но я рекомендую вам создать выделенный класс задач и затем отправить его вместо этого. Для создания такого класса нам нужно выполнить следующую команду:
php artisan make:job TrackHitJob
Она сгенерирует следующий класс:
App\Jobs\TrackHitJob
Давайте переместим наш код, из метода track контроллера TrackingController в метод handle класса TrackHitJob. Метод handle должен выглядеть так:
public function handle()
{
$tracker = Tracker::where('public_id', $tracker_public_id)->first();
if ($tracker) {
$url = $request->get('url');
$hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $url]);
$previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first();
if ($previousHit) {
$previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at);
$previousHit->save();
return $previousHit->seconds;
}
return 0;
}
return -1;
}
PS: не забудьте импортировать модели Tracker и Hit, а также класс Request.
Но как передать аргументы (публичный ID трекера и сам запрос) в код отслеживания? А мы передадим их конструктору класса, а затем метод handle может использовать их следующим образом:
namespace App\Jobs;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Queue\SerializesModels;
use Illuminate\Http\Request;
use App\Tracker;
use App\Hit;
class TrackHitJob implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
private $trackerPublicID;
private $url;
public function __construct($tracker_public_id, Request $request)
{
$this->trackerPublicID = $tracker_public_id;
$this->url = $request->get('url');
}
public function handle()
{
$tracker = Tracker::where('public_id', $this->trackerPublicID)->first();
if ($tracker) {
$hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $this->url]);
$previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first();
if ($previousHit) {
$previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at);
$previousHit->save();
return $previousHit->seconds;
}
return 0;
}
return -1;
}
}
Теперь каждый раз при получении нового Hit, нам нужно отправлять новую Задачу.
Мы можем сделать это следующим образом:
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use App\Jobs\TrackHitJob;
class TrackingController extends Controller
{
public function track($tracker_public_id, Request $request)
{
TrackHitJob::dispatch($tracker_public_id, $request);
}
}
Посмотрите, какой наш контроллер тонкий и чистый.
Если вы попытаетесь отправить POST-запрос так же как вначале, то мы не заметим разницы. Мы всё также видим заходы в таблицы hits. Запрос все также, как и в прошлый раз, занимает примерно то же самое время (~100 мс).
Что происходит? Мы действительно делегируем?
Подключение Очереди
Если откроете файл .env, то обнаружите, что у нас есть переменная QUEUE_CONNECTION равная ‘sync’
QUEUE_CONNECTION=sync
это означает, что мы обрабатываем любые Задачи сразу после их отправки и делаем это синхронно.
Итак, если мы хотим получить выгоду от использования очередей, то нам нужно подключить их к чему-то другому. Другими словами, нам нужно место, куда мы можем «поставить в очередь»/сохранить задачи до их обработки.
Есть несколько вариантов. Если вы посмотрите в файл config/queue.php, то увидите, что Laravel из коробки поддерживает сразу несколько видов подключений (“sync”, “database”, “beanstalkd”, “sqs”, “redis”).
Поскольку мы только начинаем работу с Очередями и Задачами, то давайте пока не трогать подключения требующие сторонних служб (beanstalkd и sqs), либо приложений, которых у нас может и не быть (redis). Остается database (база данных).
Таким образом, каждый раз, когда мы получаем новую Задачу, она будет сохраняться в базе данных (в специальной таблице). И потом уже оттуда она будет взята и обработана.
PS: если вы используете локальный сервер разработки, то не забудьте перезапустить его, иначе изменения, внесенные вами в файл .env, не заработают.
QUEUE_CONNECTION=database
Прежде, чем мы попытаемся отправить POST-запрос, нам нужно создать таблицу, в которой будут храниться задачи. К счастью, у Laravel есть команда, которая сгенерирует для нас эту таблицу.
php artisan queue:table
Она только создает миграцию и нам нужно выполнить миграцию этой таблицы.
php artisan migrate
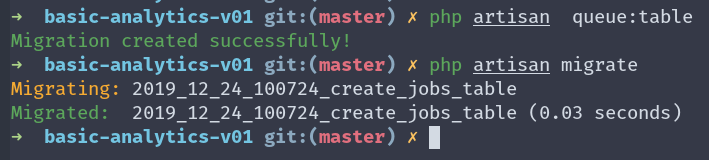
Теперь, если мы отправим запрос POST еще раз, мы увидим следующее:
- время ответа стало меньше (поскольку теперь обработка запроса не синхронна).
- мы можем увидеть новую запись в таблице:
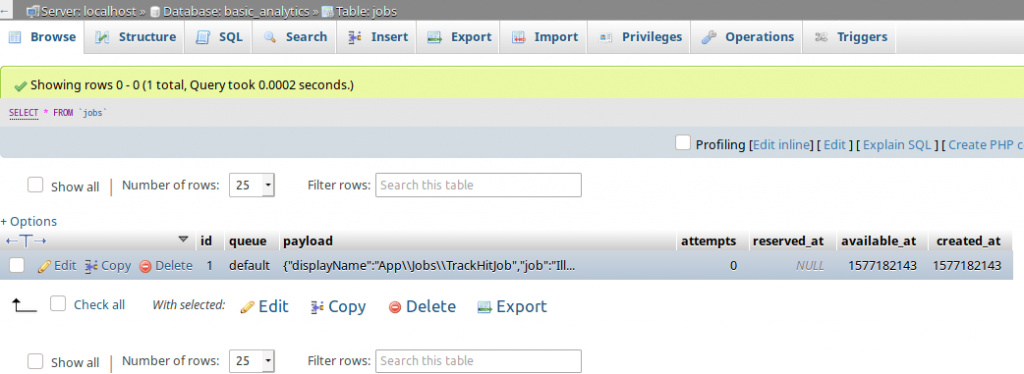
- но в таблице
hitsновых записей нет.
А их нет, потому что у нас нет никаких процессов обрабатывающих задачи из очереди. Для этого нам нужно выполнить следующую команду:
php artisan queue:work
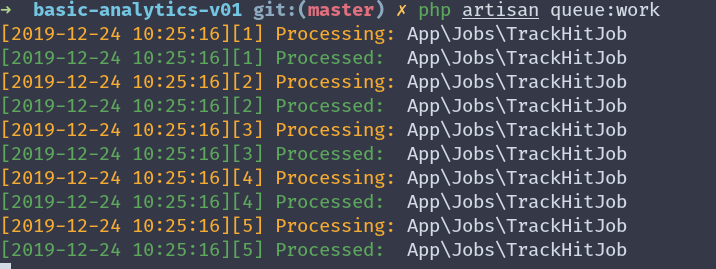
➜ basic-analytics-v01 git:(master) ✗ php artisan queue:work [2019-12-24 10:25:16][1] Processing: App\Jobs\TrackHitJob [2019-12-24 10:25:16][1] Processed: App\Jobs\TrackHitJob [2019-12-24 10:25:16][2] Processing: App\Jobs\TrackHitJob [2019-12-24 10:25:16][2] Processed: App\Jobs\TrackHitJob [2019-12-24 10:25:16][3] Processing: App\Jobs\TrackHitJob [2019-12-24 10:25:16][3] Processed: App\Jobs\TrackHitJob [2019-12-24 10:25:16][4] Processing: App\Jobs\TrackHitJob [2019-12-24 10:25:16][4] Processed: App\Jobs\TrackHitJob [2019-12-24 10:25:16][5] Processing: App\Jobs\TrackHitJob [2019-12-24 10:25:16][5] Processed: App\Jobs\TrackHitJob
Обратите внимание, что команда не завершается, она будет ожидать новых задач для обработки.
Если вам стало интересно, как запустить эту команду на продакшн-сервере и как оставить её работать после вашего логаута, то не беспокойтесь, об этом мы поговорим позже.
Если вы теперь посмотрите в таблицу jobs, то увидите, что она пуста, так как все задачи обработаны.
Параллельная обработка нескольких задач
После того, как вы увидели, что можно отправлять задачи и обрабатывать их асинхронно (т.е. нам не нужно ждать их завершения), давайте перейдем ко второй причине, по которой мы используем Задачи и Очереди: параллелизм.
Если вы внимательно следили за уроком, то заметили, что, хотя мы и распределяем задачи и делегируем их, но мы по-прежнему обрабатываем их по одной.
Решение очень простое, откройте новую вкладку терминала и выполните ту же самую команду php artisan queue:work. В следующий раз, когда вы отправите несколько POST-запросов в ваше приложение и у вас появится несколько задач в очереди, то заметите, что процессы на обеих вкладках обрабатывают задачи, а это значит, что мы обрабатываем их параллельно, и чем больше у вас процессов, тем быстрее вы очищаете свою очередь.
Опять же, если вам интересно, как это сделать на продакшн-сервере, не беспокойтесь, мы рассмотрим это позже.
Работа с проваленными задачами (failed jobs)
А теперь представьте, что вы добавили на свой сервер новый код, который привел к ошибке. Прежде, чем вы её обнаружили прошло некоторое время, а это означает, что все запросы, полученные вашим приложением за этот период, просто не были обработаны. Есть ли способ их не потерять и обработать позже, после исправления вашей ошибки? Ведь нельзя просто попросить своего клиента повторно отправить вам свои запросы (это просто невозможно). К счастью, данные не теряются, и мы можем без проблем повторить попытку обработки проваленных задач.
Но прежде чем мы рассмотрим, как мы это сделать, давайте почитаем справку команды queue:work:
php artisan queue:work --help
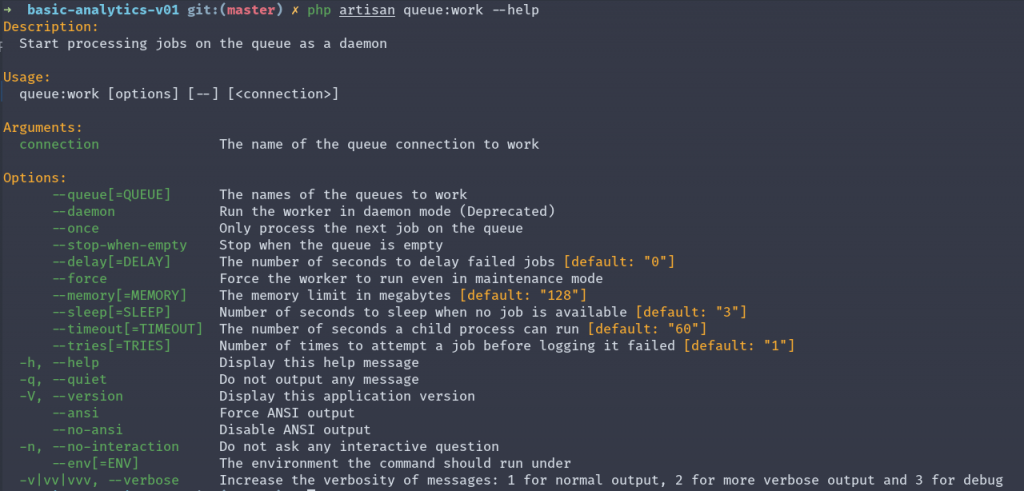
Обратите внимание, что команда может принимает несколько аргументов. Сейчас нас интересует аргумент tries
--tries[=TRIES] Количество попыток обработать задачу до того как она будет записана как проваленная [по умолчанию: "1"]
Этот аргумент помогает нам определить, сколько раз мы повторяем попытку обработать задачу, прежде чем пометить ее как проваленную.
Обратите внимание, что дефолтным значением является 1. Это означает, что сразу после первой неудачи, оно будет помечено как проваленное.
Когда обработка задачи неудачна, то она сохраняется в таблице failed_jobs. У Laravel есть команда, которая создает миграцию для этой таблицы:
php artisan queue:failed-table
Другими словами, если вы работаете с задачами и очередями в своем приложении, то вам нужно будет выполнить эту команду и ее миграцию.
Теперь давайте остановим все процессы queue:work и попробуем сымитировать неудачную задачу.
Добавим следующую строку в начало метода handle():
throw new \Exception("Error Processing the job", 1);
И обработка задачи будет каждый раз завершаться неудачно. Отправьте несколько новых POST-запросов и давайте посмотрим, что произойдет.

Как вы видите, задачи не обрабатываются. Если мы посмотрим таблицу failed_jobs, то найдем более подробную информацию о произошедшем.
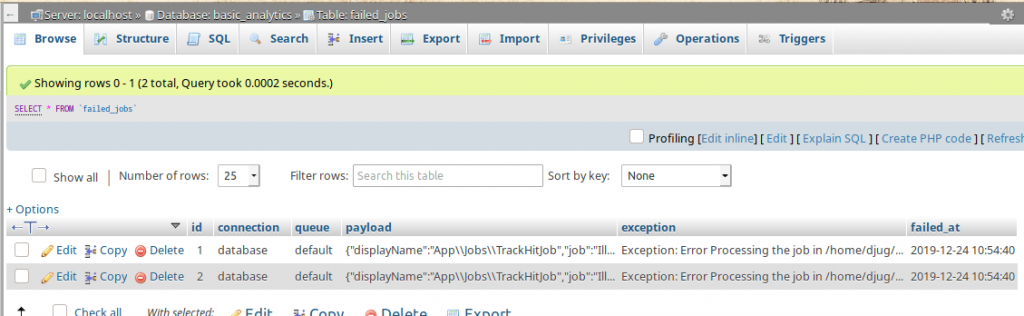
Мы можем узнать полезную нагрузку, исключение, из-за которого произошел сбой, а также подключение, очередь и время сбоя.
Теперь давайте уберем строку с исключением, и попробуем снова выполнить эти задачи.
Мы можем повторить попытку обработать все проваленные задачи или выбрать одну конкретную вот таким вот образом (замените all идентификатором задачи):
php artisan queue:retry all
Если вы не остановили предыдущий процесс queue:work перед повторной попыткой выполнения задач, вы увидите, что повторные попытки снова завершились неудачно. Почему так происходит?
Согласно документации Laravel :
Воркеры очереди — это долгоживущие процессы, сохраняющие в памяти состояние загруженного приложения. В результате они не могут увидеть изменения вашего кода после своего запуска. Поэтому после развертывания приложения обязательно перезапустите воркеры.
Соответственно, мы должны перезапустить этот процесс.
В качестве альтернативы, и если вы хотите избежать перезапуска процесса каждый раз, когда вы что-то меняете в коде, то вы можете использовать следующую команду:
php artisan queue:listen
Но, согласно официальной документации, эта команда не такая эффективная, как queue:work:
Теперь давайте снова запустим процесс queue:work и повторим все проваленные задачи.
Задания будут обработаны, и вы увидите новые записи в таблице hits.
Что дальше
В следующем уроке вы узнаете, как использовать другие подключения, мы рассмотрим использование нескольких очередей и как сделать некоторые задачи/очереди более приоритетными.
Далее мы рассмотрим, как нужно развертывать наше приложение, основанное на задачах и очередях, и что нужно сделать, чтобы поддерживать процессы в рабочем состоянии.
Автор: Youghourta Benali
Перевод: Алексей Широков
Наш  Телеграм-канал — следите за новостями о Laravel.
Телеграм-канал — следите за новостями о Laravel.