
Меня очень волнует производительность приложений, в том числе, как для этого использовать слой базы данных. Сегодня я хочу поделиться с вами правилом, которое я использую при написании своих приложений:
Насколько возможно, оптимизируйте запросы к базе данных в периметре ваших приложений.
Что я имею в виду? Проще говоря, это означает проектирование вашего приложения таким образом, чтобы вы могли использовать жадную загрузку и фильтацию отношений модели в контроллерах.
Снова и снова я вижу, как разработчики сталкиваются с проблемами производительности, потому что они запускают запросы к базе данных в своих моделях, ресурсах, шаблонах и сервисах. Каждый раз, как вы это делаете, вы лишаете свои контроллеры возможности оптимизировать эти запросы.
Давайте рассмотрим всё это на примере.
Пример простого приложения
Допустим, у нас есть очень простое приложение для домашней библиотеки, которое отслеживает книги, которыми кто-то владеет. Наши модели могут выглядеть так:
class User extends Model
{
public function books()
{
return $this->belongsToMany(Book::class)
->withPivot('favourite');
}
}
class Book extends Model
{
public function authors()
{
return $this->belongsToMany(Author::class);
}
}
class Author extends Model
{
public function books()
{
return $this->belongsToMany(Book::class);
}
}
А теперь представьте, что мы хотим создать страницу, на которой отображались бы любимые книги (favourite books) конкретного пользователя. Мы могли бы создать следующий контроллер:
class FavouriteBooksController extends Controller
{
public function index(User $user)
{
return View::make('favourites', ['user' => $user]);
}
}
Поскольку мы хотим показывать только любимые книги, то нам нужно как-то отфильтровать книги пользователя, чтобы показывались только любимые. Обычный подход заключается в добавлении нового метода favouriteBooks() в модель User:
class User extends Model
{
public function books()
{
return $this->belongsToMany(Book::class)
->withPivot('favourite');
}
public function favouriteBooks()
{
return $this->books()
->where('favourite', true)
->with('authors')
->get();
}
}
Мы уже ученые и используем жадную загрузку для авторов, так как не хотим создавать проблему N+1 и знаем, что в нашем шаблоне для каждой книги нужно отображать имена авторов.
И, наконец, создадим шаблон для отображения всех любимых книг пользователя.
<h1>{{ $user->name }}’s Favourite Books</h1>
@foreach($user->favouriteBooks() as $book)
<h2>{{ $book->title }}</h2>
<div>Authors: {{ $book->authors->implode('name', ', ') }}</div>
@endforeach
Прекрасно! Контроллер, шаблон и модели — всё понятно и лаконично. И у нас даже есть новый метод favouriteBooks(), который мы потом пригодится и в других местах нашего приложения.
Но, притормозите.
Специфические вопросы производительности
Мы только что получили две специфические проблемы с производительностью.
Во-первых, теперь мы заставляем наше приложение загружать всех авторов каждый раз, когда мы вызываем метод favouriteBooks(). Это может легко означать ненужные запросы к базе данных в других частях нашего приложения, которые вообще не требуют авторов. И эта проблема только усугубится, если нам когда-нибудь понадобится больше информации о книгах. Например, может быть, мы добавим информацию об издателе как дополнительное отношение.
Во-вторых, мы сделали невозможным жадную загрузку всех любимых книг группы пользователей, поскольку метод favouriteBooks() будет выполнять полный запрос к базе данных для каждого пользователя. Это не проблема для нашей страницы, ведь она показывает только одного пользователя, но на странице, которая будет отображает много пользователей, это приведет к проблеме N+1.
Здесь мы действительно создали вспомогательный метод, оптимизированный для одного очень конкретного случая использования в нашем приложении. Однако, он выглядит так, что его можно использовать в разных случаях. Но это почти наверняка приведет к проблемам с производительностью в будущем.
Перенос оптимизаций на периметр
Основная проблема при выполнении запросов к БД непосредственно в моделях заключается в том, что модель не может знать контекст, в котором она используется, и, следовательно, не может произвести необходимую оптимизацию. И это касается не только моделей, но и ресурсов, шаблонов, сервисов и любого вложенного слоя вашего приложения.
Контроллеры, с другой стороны, полностью осведомлены о контексте и точно знают, какие данные требуются для каждой конкретной конечной точки. Это позволяет им наилучшим образом оптимизировать запросы к базе данных.
Давайте сделаем рефакторинг нашего примера и перенесем эти оптимизации в контроллер.
Во-первых, обновим метод favouriteBooks(), чтобы он работал с коллекцией books в памяти, а не в конструкторе запросов, дабы избежать каких-либо запросов к базе данных в модели User .
class User extends Model
{
public function books()
{
return $this->belongsToMany(Book::class);
}
public function favouriteBooks()
{
// return $this->books()->where('favourite', true)->with('authors')->get();
return $this->books->where('pivot.favourite', true);
}
}
Вы, наверное, уже думаете: «Но разве это не сделает запрос к базе данных, ведь Laravel будет использовать ленивую загрузку для отношения с книгами?» И вы были бы правы, если мы просто остановились бы на этом. Однако здесь есть очень важное отличие. Ссылаясь на коллекцию books в памяти вместо конструктора запросов, мы можем оптимизировать, как и когда выполняется этот запрос к базе данных.
Продолжим оптимизацию.
В нашем контроллере мы будем использовать метод load() в модели $user, чтобы использовать жадную загрузку только любимых книг пользователя, а также авторов этих книг.
class FavouriteBooksController extends Controller
{
public function index(User $user)
{
$user->load(['books' => function ($query) {
$query->where('favourite', true)->with('authors');
}]);
return View::make('favourites', ['user' => $user]);
}
}
Вот и все! Теперь мы перенесли оптимизацию запросов к базе данных этой страницы в контроллер, что позволило нам идеально оптимизировать ее для этой конечной точки. Кроме того, наша модель больше не выполняет запросы к базе данных и не беспокоится о том, чтобы загружать отношения авторов.
Потрясающе!
Оптимизация другой страницы
Давайте посмотрим, как это работает на другом эндпоинте. Представим, что у пользователей есть друзья, и они могут видеть список всех своих друзей на странице со своими любимыми книгами. Мы можем использовать ту же самую технику, чтобы загрузить все любимые книги друга.
class FriendsController extends Controller
{
public function index(User $user)
{
$user->load(['friends.books' => function ($query) {
$query->where('favourite', true);
}]);
return View::make('friends', ['user' => $user]);
}
}
Мы можем повторно использовать метод favouriteBooks() для отображения друзей в шаблоне этой страницы. И, поскольку мы отрефакторили этот метод, и запроса к БД больше нет, то мы можем загружать все книги друзей в контроллере и избежать проблемы N+1 для каждого друга.
Кроме того, поскольку мы не показываем авторов на этой странице, мы можем просто не указывать жадную загрузку для авторов и избежать загрузки ненужных данных.
<h1>{{ $user->name }}’s Friends</h1>
@foreach($user->friends as $friend)
<h2>{{ $friend->name }}</h2>
<ul>
@foreach($friend->favouriteBooks() as $book)
<li>{{ $book->title }}</li>
@endforeach
</ul>
@endforeach
Давайте сравним результаты между нашим исходным решением (которое было оптимизировано только для первой страницы) и нашей версией с рефакторингом. Предположим, что у нас есть 10 друзей, у каждого из которых есть 5 любимых книг, и у каждой книги есть 1 автор.
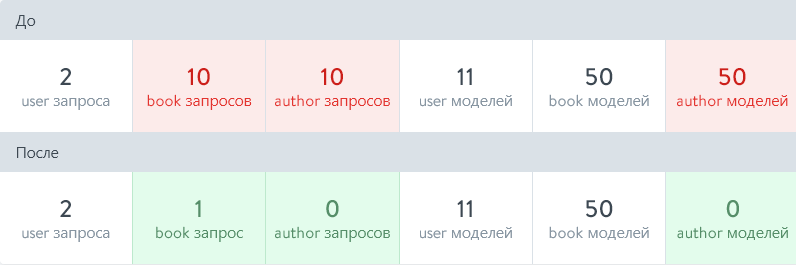
Как вы видите, получился довольно неплохой выигрыш в производительности. Этот рефакторинг привел к уменьшению количества запросов к базе данных на 19 и уменьшению гидратации моделей на 50. Хотя, если честно, это довольно невинный пример. Мне кажется, гораздо хуже будет в производственных приложениях, где подобные проблемы приводили к тому, что конечные точки выполняли более 1000 запросов к базе данных!
Общее правило
Я считаю полезным писать свои модели так, как будто все данные отношений уже загружены. Это означает, что я не выполняю запросы к базе данных непосредственно в моделях, а вместо этого работаю с данными отношений в памяти.
Делая так, вы упрощаете модели и им больше не нужно будет беспокоиться о проблемах с производительностью. Еще важнее то, что вы создаете свое приложение таким образом, что оно позволяет вашим контроллерам выполнять любые необходимые оптимизации запросов к базе данных.
Но мои контролеры теперь уродливы
Вы, наверное, думаете: «Ладно, это здорово, Джонатан, но мои контролеры теперь выглядят грязно». Вы правы, так и есть. И я согласен на такую сделку. Я, скорей всего, немного приберусь, используя скоупы для основных запросов. Например, я бы добавил скоуп favourite() в модель Book.
class FriendsController extends Controller
{
public function index(User $user)
{
$user->load(['friends.books' => function ($query) {
$query->favourite();
}]);
return View::make('friends', ['user' => $user]);
}
}
И PHP 7.4 сделает это еще прекраснее ?
class FriendsController extends Controller
{
public function index(User $user)
{
$user->load(['friends.books' => fn ($query) => $query->favourite()]);
return View::make('friends', ['user' => $user]);
}
}
Разве вы не дублируете код?
Вы можете задаться вопросом, не означает ли этот подход постоянное дублирование кода в методах модели и оптимизациях контроллера. Например, разве оба, и метод favouriteBooks(), и контроллер фильтрующий книги, не направлены только на фильтрацию любимых книг?
И да, и нет.
В некоторых ситуациях вы дублируете логику. Тем не менее, я вижу их как две разные вещи. В нашем примере метод favouriteBooks() в конечном итоге отвечает за то, чтобы возвращались только любимые книги. Этот метод обеспечивает правильную работу приложения. С другой стороны, оптимизация контроллера не отвечает за обеспечение правильного функционирования приложения, а скорее за его адекватную работу. Считайте это прогрессивным усовершенствованием. Приложение работает в любом случае, но с ними лучше.
Во (многих) других ситуациях это не так просто, и метод модели будет выполнять гораздо больше работы, чем просто оптимизация контроллера. Это может включать преобразования, вычисления и другие общие задачи.
Например, в моем SaaS приложении у меня есть модель Family, в которой есть метод name(). Этот метод генерирует строку (например, Jonathan & Amy Reinink) на основе имени и фамилии основного члена семьи, а также имени и фамилии их супруга. Он использует записи о браке основного члена семьи, чтобы определить, кто является текущим супругом. Оттуда он проверяет, совпадают ли фамилии (игнорируя символы, которые не имеют значения, такие как пробелы), и, если они совпадают, включает фамилию только один раз. Для этого метода важно, чтобы контроллер должным образом загружал правильные данные об отношениях пользователя и брака, но и все. Остальная часть тяжелой работы лежит на методе name().
Разве вы не можете просто использовать скоуп для отношений?
Если вы все это время задавались вопросом, можно ли в этой ситуации просто использовать скоуп для отношений, то ответ — да. Вот как:
class User extends Model
{
public function books()
{
return $this->belongsToMany(Book::class);
}
/**
* @return \Illuminate\Database\Eloquent\Relations\BelongsToMany
*/
public function favouriteBooks()
{
// Заметьте, что мы не вызываем get() в конце
return $this->books()->where('favourite', true);
}
}
Теперь вы можете взаимодействовать с отношениями favouriteBooks также, как и с отношениями books. Вы можете использовать жадную загрузку вместе с любыми дочерними отношениями прямо из контроллера.
Я решил использовать этот пример, потому что он прост в использовании. Тем не менее, существует много ситуаций, когда скоуп отношения не будут работать (например, выше приведенный пример с фамилией), и тогда методы, описанные в этой статье, будут чрезвычайно полезны.
Это все, что я хотел рассказать. Я надеюсь, что эта статья оказалась вам полезной! Вперед к быстрым приложениям!
Автор: Jonathan Reinink
Перевод: Алексей Широков
Наш  Телеграм-канал — следите за новостями о Laravel.
Телеграм-канал — следите за новостями о Laravel.